
Tanto en el área de servicios como en la de sistemas de producción, en los que se sirven o fabrican unidades cuyas calidades se describen mediante una variable normal X, interesa comprobar que su media se mantiene próxima al valor nominal μ. Adicionalmente, se debe comprobar que la variabilidad no sea tan grande como para que haya un número apreciable de unidades fuera del intervalo de tolerancia.
El procedimiento para el control de la variabilidad requiere ir tomando pequeñas muestras de tamaño n a intervalos regulares de tiempo. Llamando xij a la j-ésima observación de la i-ésima muestra, se calculan la media y la desviación típica de cada una de las muestras: ˉxi=1nn∑j=1xij y si=√1n−1n∑j=1(xij−ˉxi)2 siendo i∈{1,…,m}, con m el número total de muestras realizadas.
Si nos centramos en el control de la variabilidad, disponemos de una secuencia de m cuasidesviaciones típicas (s1,s2,…,sm). Si el proceso se mantiene bajo control, esperamos que estos valores fluctúen alrededor de un valor central no más allá de tres desviaciones típicas; la comprobación de esta hipótesis es el objeto del gráfico de control de las desviaciones.
El valor central buscado es la esperanza de las cuasidesviaciones típicas, cuyo estimador natural es la media de las cuasivarianzas observadas, ˉs=1mm∑i=1si, que es un estimador insesgado de E[S], ya que E[ˉS]=E[1mm∑i=1Si]=1m⋅m⋅E[Si]=E[Si],∀i.
Necesitamos ahora conocer y estimar la desviación típica de las Si. Es bien conocido que la cuasivarianza muestral S2i es un estimador insesgado de la varianza de la población σ2, ya que (n−1)S2σ2∼χ2n−1. Pero Si no es un estimador insesgado de la desviación típica de la población, σ; sin embargo, sí es cierto que √n−1Siσ∼χn−1, donde χn−1 hace referencia a la distribución con densidad f(x)=21−n−12xn−2e−x22Γ(n−12),∀x≥0.
Es fácil calcular la esperanza de esta distribución con el programa Maxima,
f(x) := 2^(1-(n-1)/2)*x^(n-2)*%e^(-x^2/2) /
gamma((n-1)/2) $
declare(n, integer)$
assume (n>0)$
m1: radcan(integrate(x*f(x),x,0,inf));
√2Γ(n2)Γ(n−12)
Como consecuencia de lo anterior tenemos que E[√n−1Siσ]=√2Γ(n2)Γ(n−12), o también, E[Si]=√2Γ(n2)σ√n−1Γ(n−12)=c4σ, donde hemos nombrado c4 al coeficiente de σ.
Vamos ahora con la varianza de las Si. Seguimos utilizando Maxima para calcular el momento de segundo orden,
m2: radcan(integrate(x^2*f(x),x,0,inf)); /* ayudamos a simplificar, haciéndole ver al programa que (n+1)/2=(n-1)/2+1 */ gamma_expand:true$ m2: subst([(n+1)/2=(n-1)/2+1], m2);
n−1
Finalmente obtenemos la varianza
m2 - m1^2;
−2Γ2(n2)Γ2(n−12)+n−1
Acabamos de demostrar que V[√n−1Siσ]=n−1−2Γ2(n2)Γ2(n−12), o también, V[Si]=(1−2Γ2(n2)(n−1)Γ2(n−12))σ2=(1−c24)σ2.
Recapitulando, el gráfico de control para las desviaciones deberá basarse en la banda ˉs∓3⋅√1−c24σ, en el que ˉs estima la esperanza de las Si. En general, desconoceremos la desviación típica de la población, por lo que queda buscarle un buen estimador a σ.
Reparamos en el siguiente cálculo: E[ˉSc4]=1c4E[1m∑mi=1Si]=1c4⋅1m⋅m⋅E[Si]=1c4c4σ=σ. Por lo tanto, ˉS/c4 es un estimador insesgado de σ.
Así pues, la banda para el gráfico de control del 99% para la desviación típica viene dado por ˉs∓3⋅√1−c24ˉsc4.
Ahora es el momento de poner a funcionar todo esto. Partimos de una muestra
m: [[4.8, 5.3, 4.9, 4.9],
[5.0, 4.3, 5.1, 5.6],
[5.9, 5.5, 6.0, 4.6],
[4.3, 5.3, 3.8, 4.8],
[4.8, 6.0, 4.8, 5.0],
[6.0, 4.4, 4.3, 4.6],
[4.8, 6.4, 4.7, 4.9],
[5.1, 4.1, 6.1, 5.5],
[5.3, 5.0, 3.0, 5.0],
[5.3, 4.3, 4.1, 4.3],
[4.4, 6.3, 5.1, 5.8],
[6.8, 4.5, 6.4, 3.7],
[5.7, 5.2, 5.0, 5.3],
[5.6, 5.9, 4.9, 4.2],
[5.0, 4.1, 4.7, 5.4],
[6.2, 4.5, 4.3, 5.2],
[5.6, 5.3, 4.9, 5.7],
[4.6, 5.0, 5.4, 4.9]] $
load(descriptive)$
s: map('std1,m)$
c4: subst([n=length(m[1])], m1/sqrt(n-1)) $
CL: mean(s)$
[UCL,LCL]: CL + 3*sqrt(1-c4^2)*CL/c4*[+1,-1] $
LCL: max(0, LCL) $
vmin: lmin(cons(LCL,s))$
vmax: lmax(cons(UCL,s))$
amp: vmax-vmin$
draw2d(
points_joined = true,
points(s),
yrange = [vmin, vmax] + 0.25*amp*[-1,+1],
/* línea central */
color = red,
points([[0,CL],[length(s),CL]]),
/* extremos de la banda */
line_type = dots,
points([[0,UCL],[length(s),UCL]]),
points([[0,LCL],[length(s),LCL]]) ) $
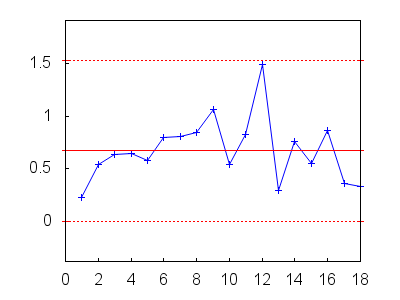
Todo indica que la variabilidad está bajo control. Aún así, convendría investigar bajo qué circunstancias se tomó la muestra número doce, ya que su valor es sensiblemente diferente al resto y sería útil saber si se debió simplemente a una fluctuación aleatoria o a otra causa, como un desajuste temporal del sistema, un operario inexperto, etc.
© 2011-2016, TecnoStats.